Code
# Load state score data
dat <- readRDS('data/state_score_iterations.rds')
# get_str(dat)
# Custom function to create spider plots
get_vt_spiders(dat, 'raw_minmax')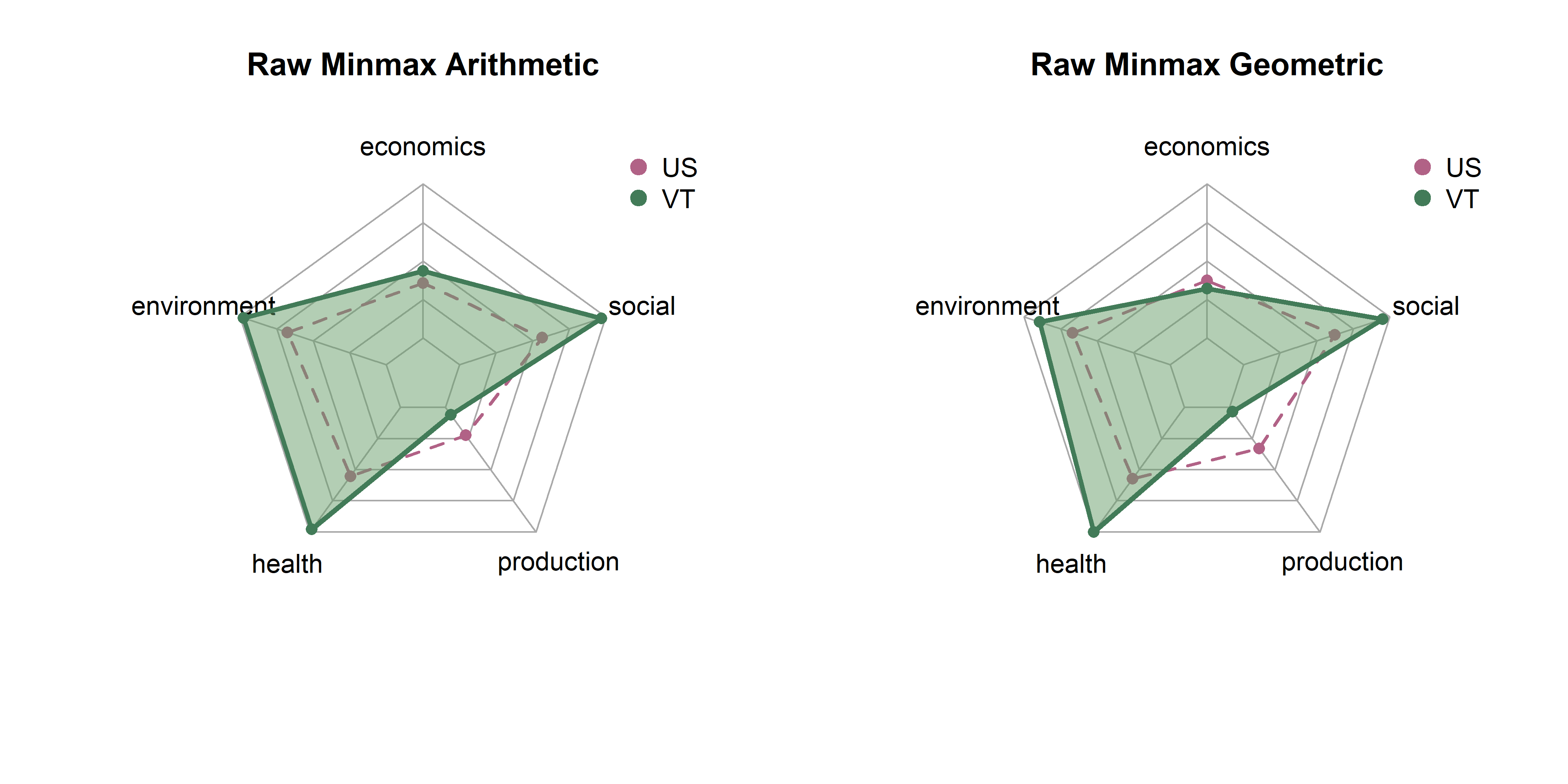
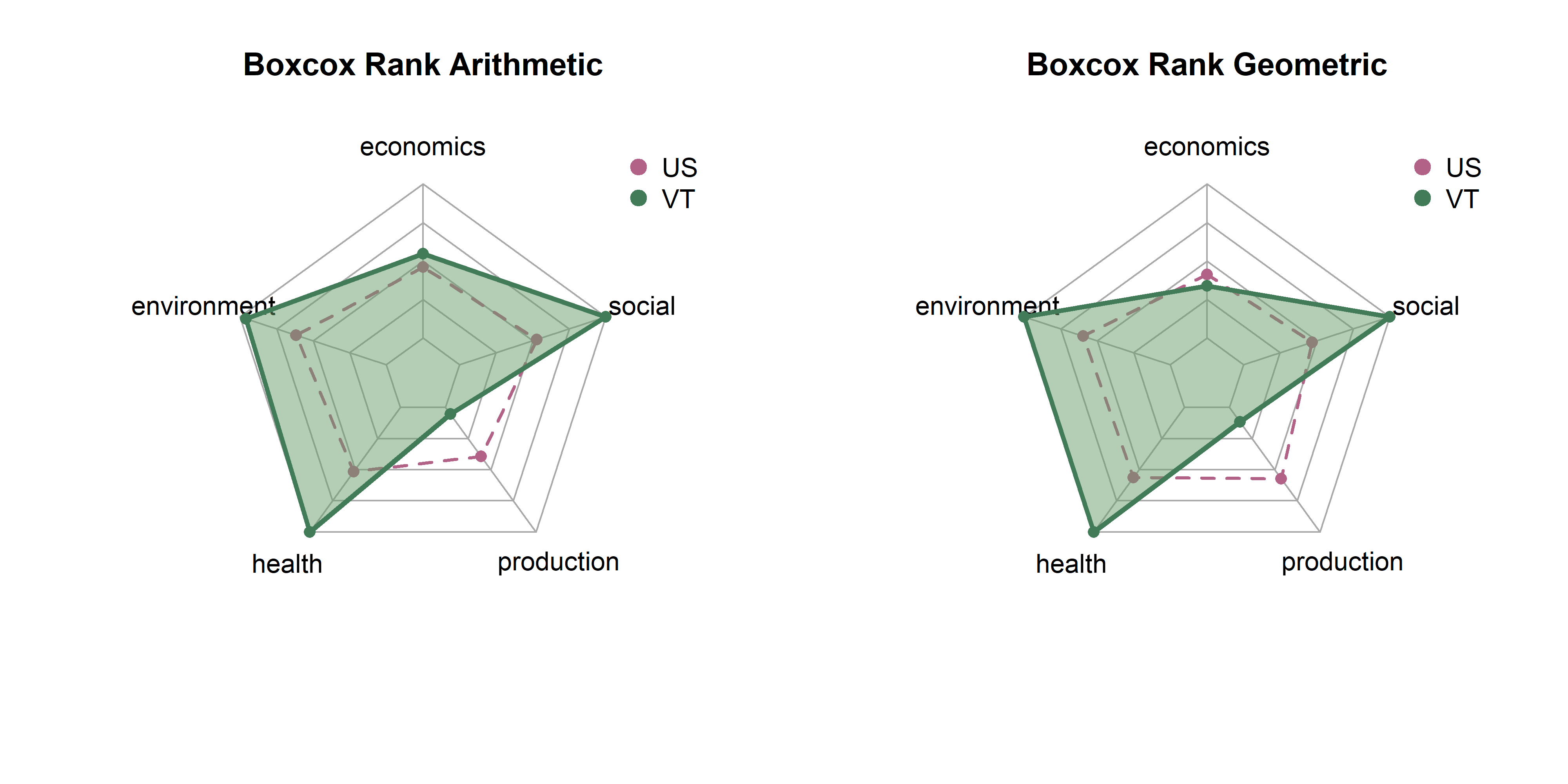
In the last page we created 18 sets of scores by state based on combinations of three transformatino methods (raw, winsor, box cox), three rescaling methods (z-scores, min max, rank) and two aggregation methods (arithmetic, geometric). Here, we will explore differences between them in terms of state distributions and rankings.
Note that each set of spider plots are scaled to the minimum and maximum of any single state in that dimension, given the rescaling and aggregation methods. This means in the case of min-max scaling, for example, raw metrics are scaled from 0 to 1, arithmetic and geometric means consolidate values to dimension scores, and these sets of dimension scores are scaled on the plot from the lowest to the highest value of any state. A “perfect” score here means that it is the best of any state. Plots show dimension values for Vermont in green. The dotted purple polygon behind it is the median of US states. Arithmetic means are on the left, and geometric on the right.
Be aware that spider/radar charts can be hard to interpret, and sometimes misleading The Radar Chart and its Caveats. The order of variables makes a big impact on the area of chart, and area is not a terribly reliable way to show differences, as it increases quadratically as variables increase linearly. Will explore some other ways to show this information, but using these for now as they are quite popular in the literature for sustainability metrics.
We are starting with min max normalization, which is probably the most intuitive transformation. Every metric is scaled from 0 to 1, so the lowest value from any state becomes 0, and the highest value from any state becomes 1. Indicators, indices, and dimensions are then aggregated using arithmetic or geometric means.
The transformation is easy to understand, but has some drawbacks, including being quite sensitive to outliers. Strong outliers in either direction could condense the rest of the distribution, making it seem like most states are very low or very high.
# Load state score data
dat <- readRDS('data/state_score_iterations.rds')
# get_str(dat)
# Custom function to create spider plots
get_vt_spiders(dat, 'raw_minmax')
get_vt_spiders(dat, 'winsor_minmax')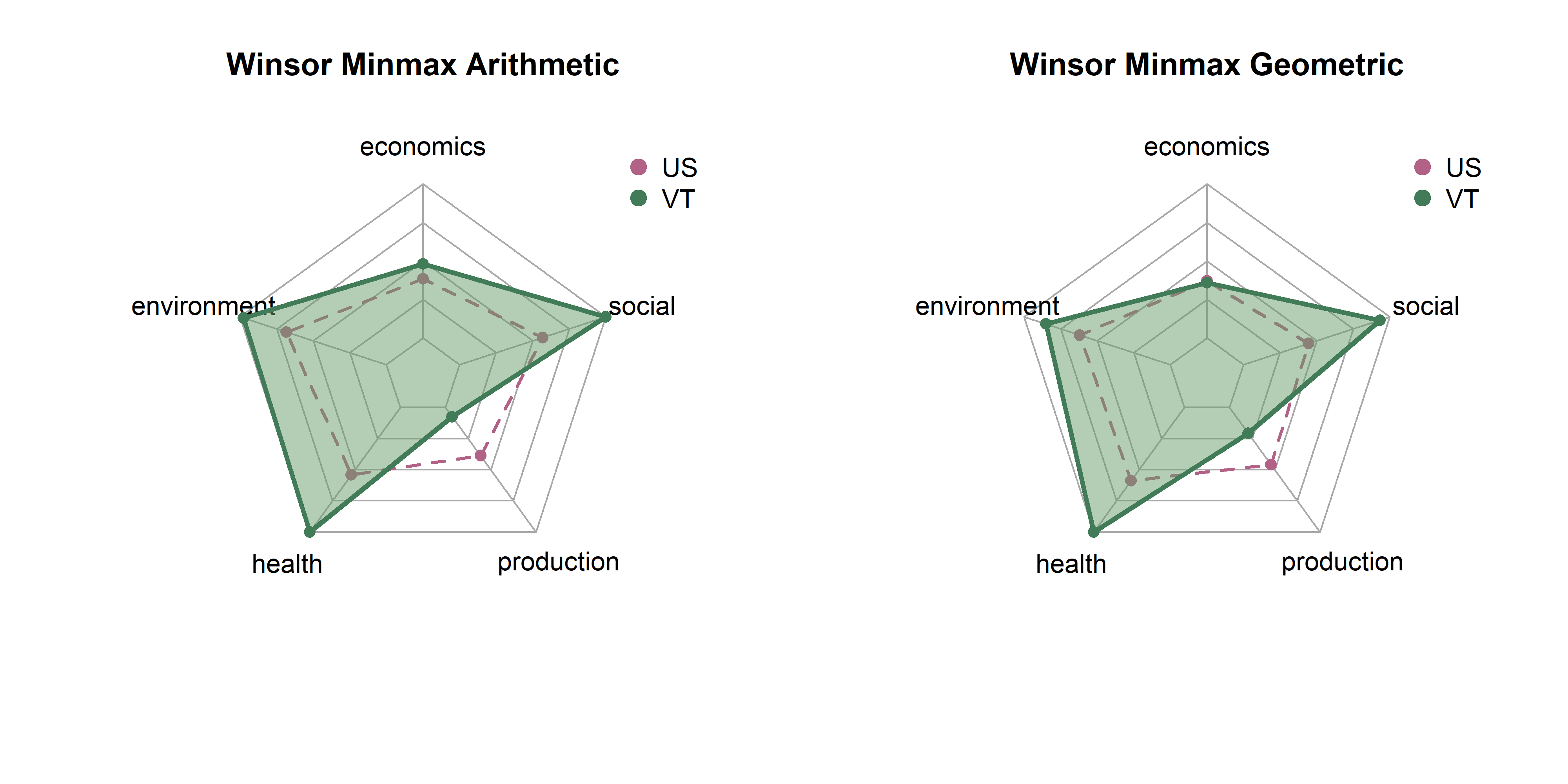
get_vt_spiders(dat, 'boxcox_minmax')
Z-scores are standardized values. We subtract the mean from every metric to center it at 0, then divide by the standard deviation to get units in terms of standard deviations. This should be more robust to outliers than the min-max method; extreme values have no effect on values. However, rescaling Z-scores to fit the spider plots might have a similar effect.
get_vt_spiders(dat, 'raw_zscore')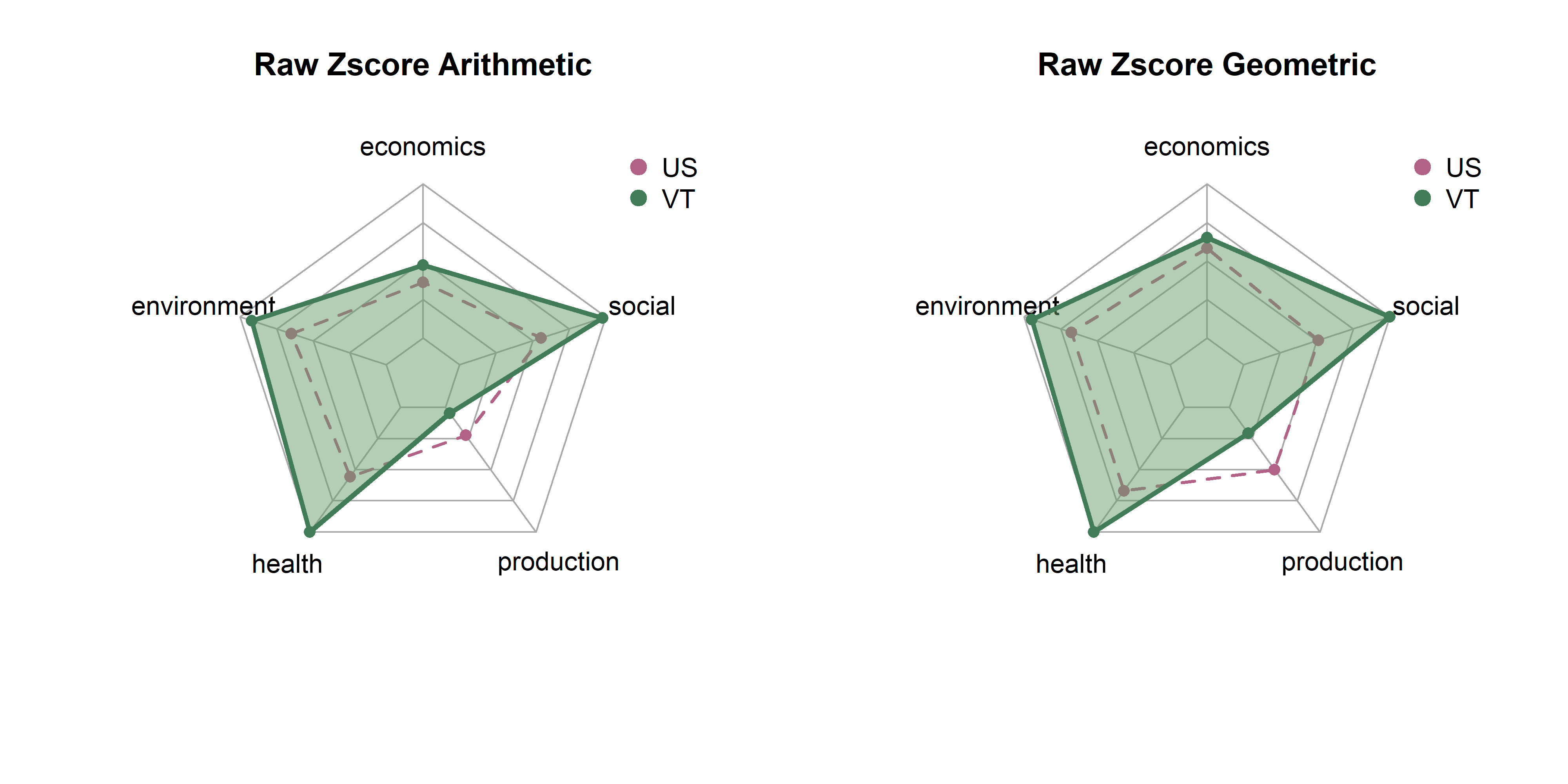
get_vt_spiders(dat, 'winsor_zscore')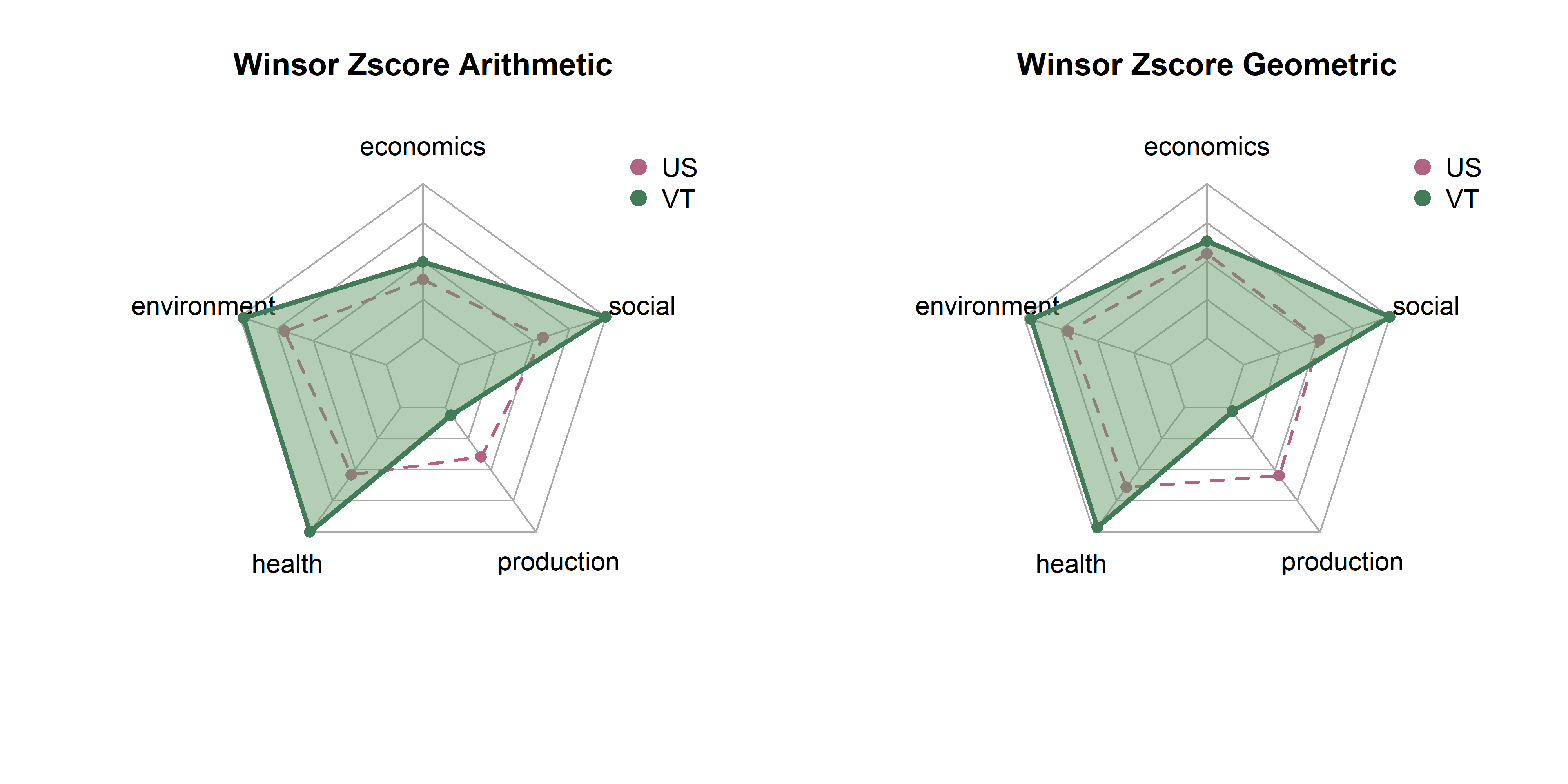
get_vt_spiders(dat, 'boxcox_zscore')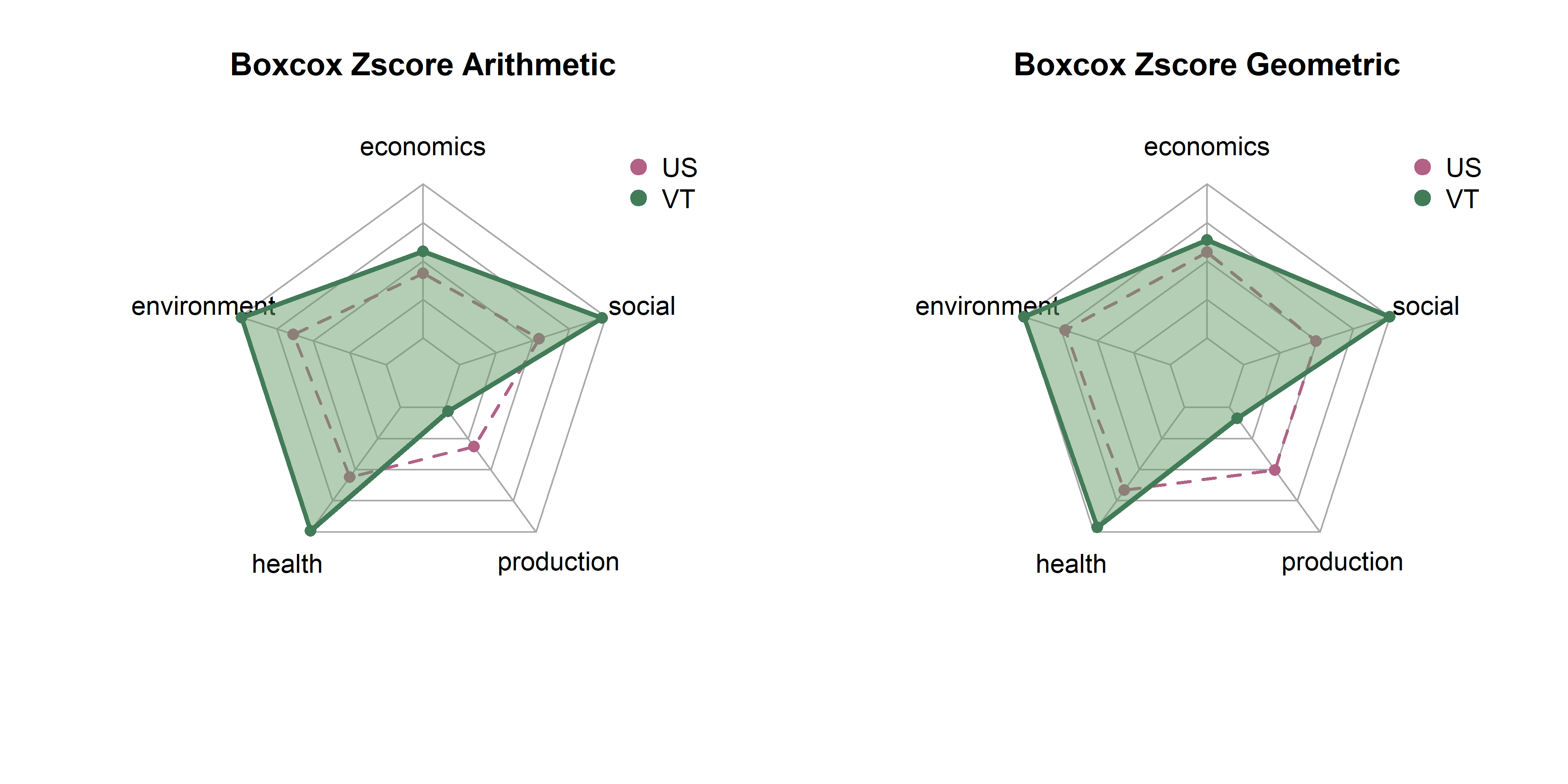
get_vt_spiders(dat, 'raw_rank')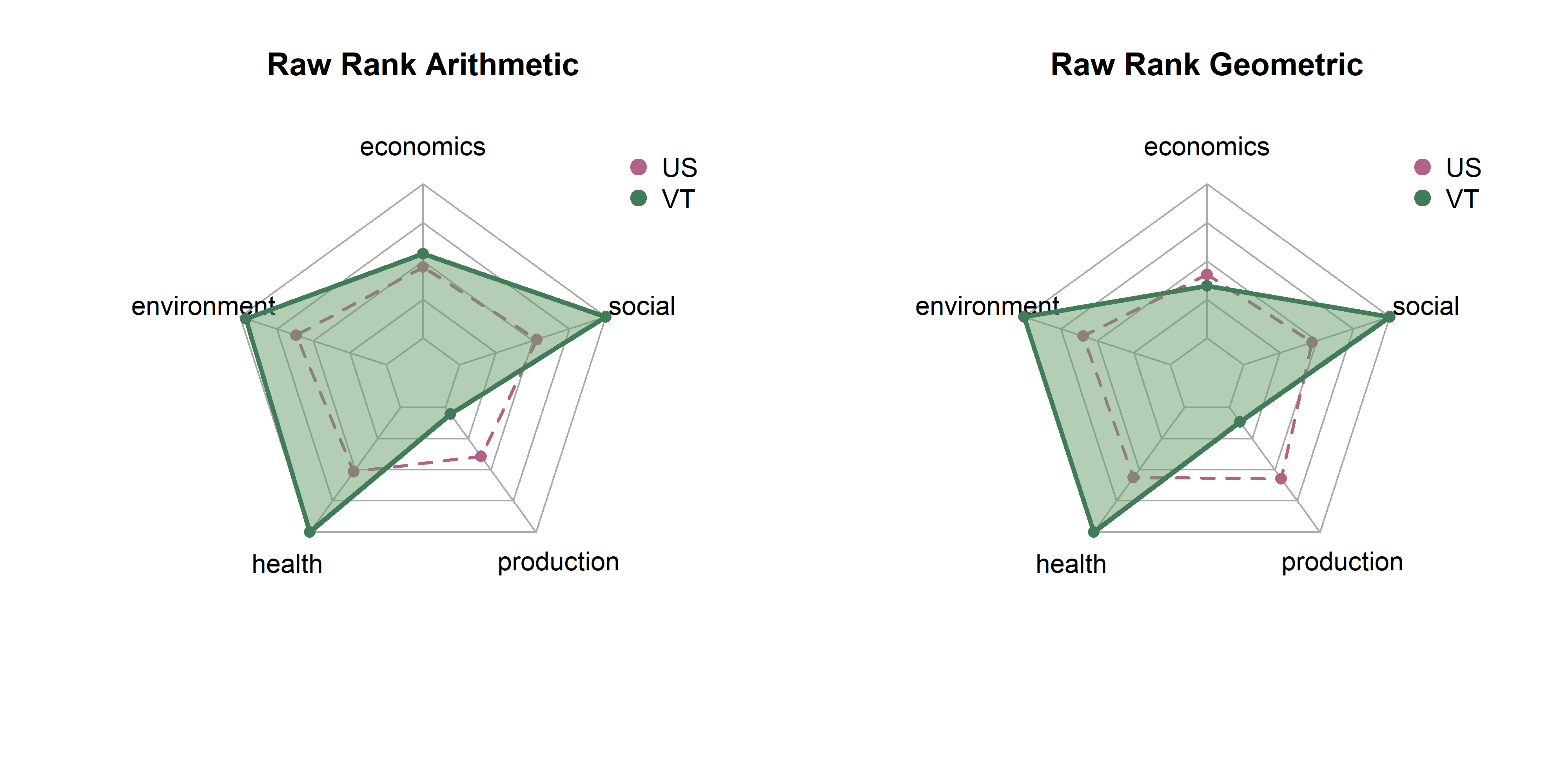
get_vt_spiders(dat, 'winsor_rank')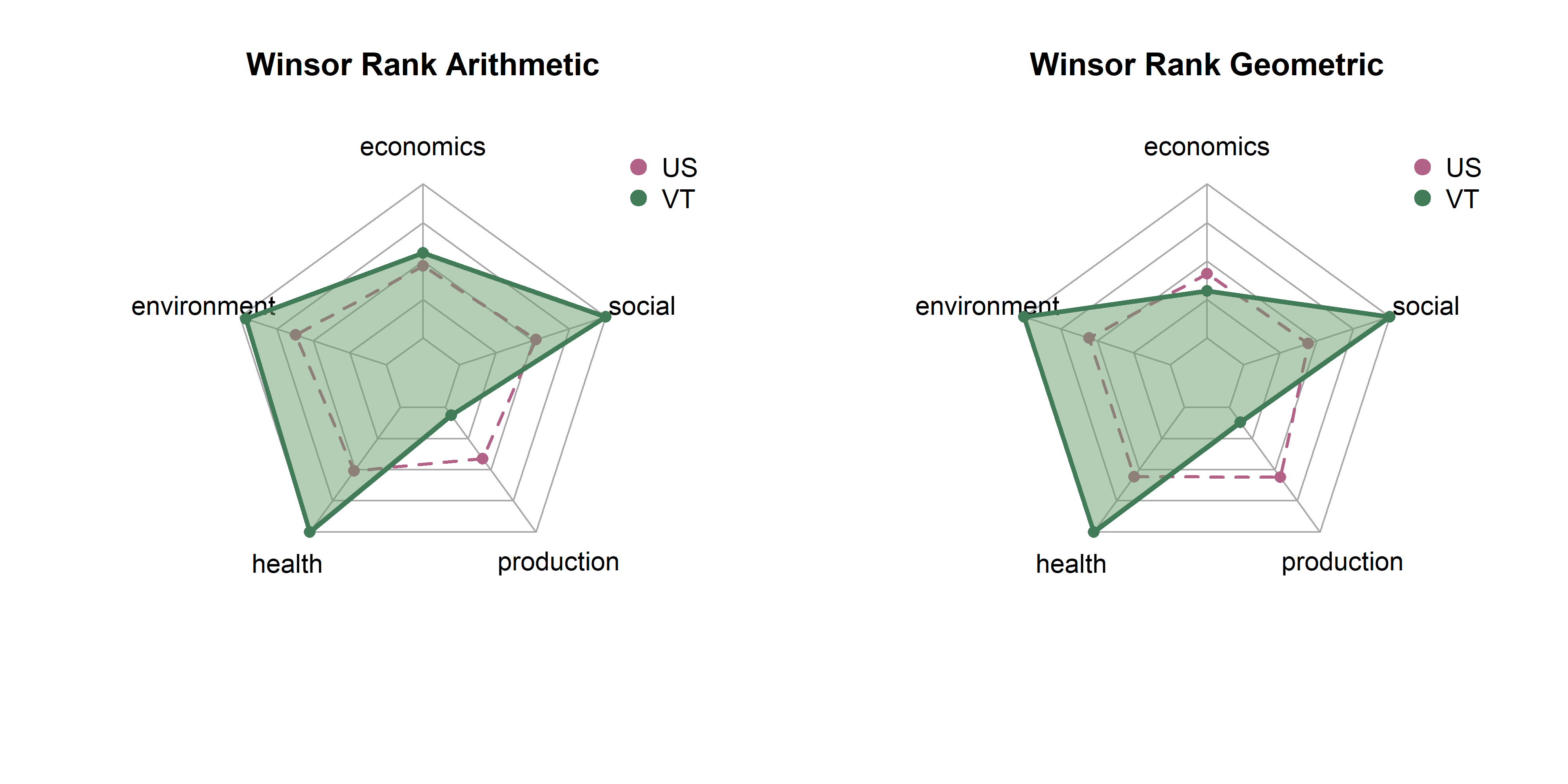
get_vt_spiders(dat, 'boxcox_rank')