tab <- SMdocs::giant_table
get_str(tab)
# Filter down to metrics in use
tab <- tab %>%
filter( metric != 'NONE' & !is.na(variable_name) )
get_str(tab)
tab %>%
group_by(source) %>%
summarize(count = n()) %>%
arrange(source)
# Need to clean up names
# String distance to consolidate sources
mat <- stringdistmatrix(tab$source, tab$source, method = "lv")
# Cluster
hc <- hclust(as.dist(mat))
# Cuttree at max edit distance
clusters <- cutree(hc, h = 4)
# Check
tab$cluster <- clusters
tab %>%
select(source, cluster) %>%
arrange(source)
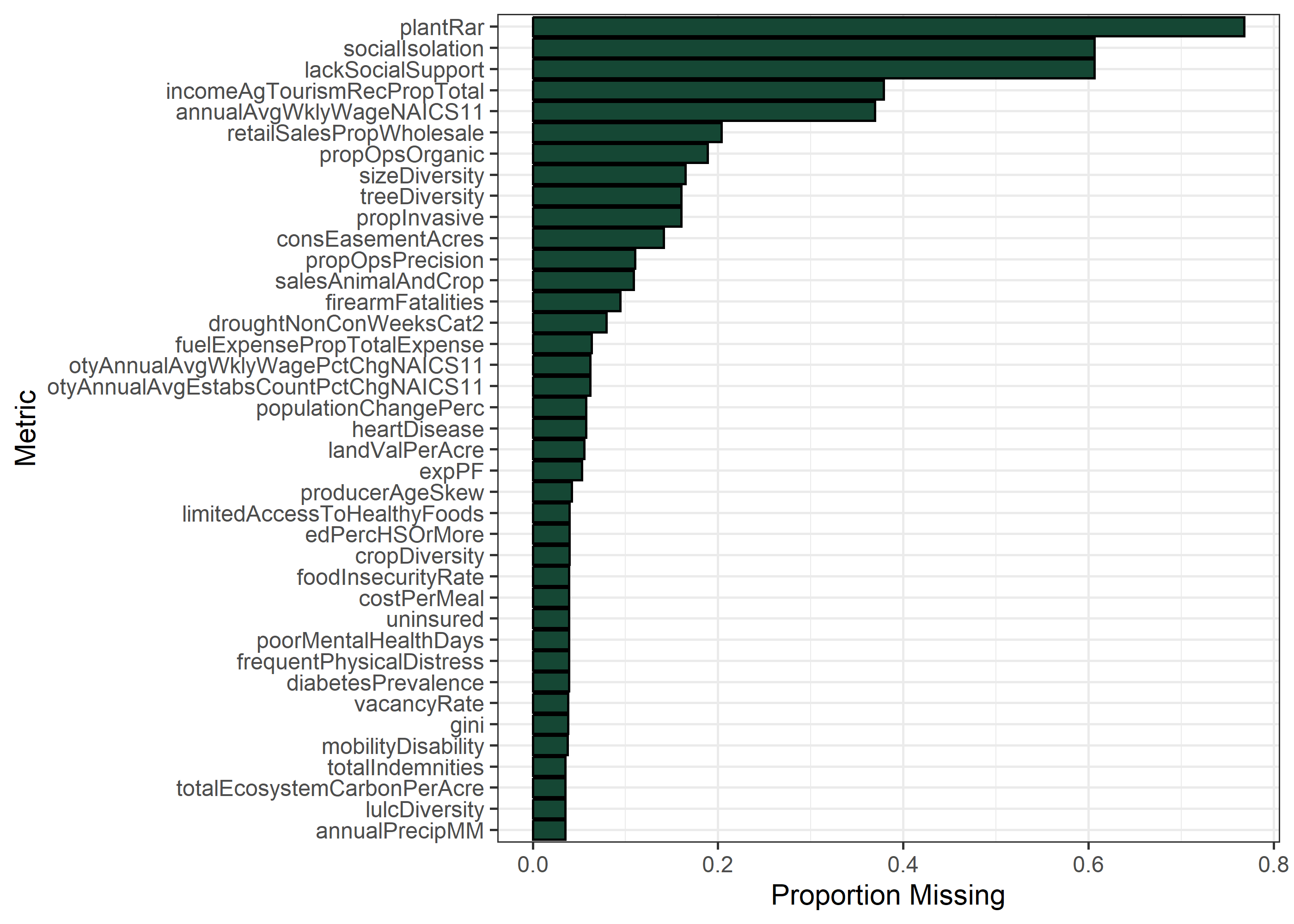
# This is less useful than I hoped - some sources have very different citations3
# because they come from different branches. Let's try manually clumping
get_str(tab)
tab <- tab %>%
mutate(
org = case_when(
str_detect(source, 'CDC|Disease Control') ~ 'CDC',
str_detect(source, 'National Agricultural Stat') ~ 'NASS',
str_detect(source, 'Madison|Wisconsin') ~ 'UWMadison',
str_detect(source, 'American Community Survey') ~ 'Census Bureau',
str_detect(source, 'Economic Research Service') ~ 'ERS',
str_detect(source, 'Forest Inventory Analysis') ~ 'USFS',
str_detect(source, 'Geological') ~ 'USGS',
str_detect(source, 'Labor Stat|BLS') ~ 'BLS',
str_detect(source, 'Environmental Protection') ~ 'EPA',
str_detect(source, 'Food and Nutrition') ~ 'Food and Nutrition',
str_detect(source, 'Carbon Monitoring') ~ 'National Carbon Forest Monitoring System',
str_detect(source, 'Bureau of Investigation') ~ 'FBI',
str_detect(source, 'Feeding America') ~ 'Feeding America',
str_detect(source, 'Drought') ~ 'USDM',
str_detect(source, 'Risk') ~ 'RMA',
str_detect(source, 'PRISM') ~ 'PRISM',
.default = source
),
usda = case_when(
org %in% c('NASS', 'ERS', 'USFS', 'FNS', 'RMA', 'ERS') ~ TRUE,
.default = FALSE
),
sector = case_when(
usda == TRUE | org %in% c(
'USDM',
'EPA',
'Carbon Monitoring',
'FBI',
'USGS',
'Census Bureau',
'CDC',
'BLS'
) ~ 'Federal',
org %in% c('UWMadison', 'PRISM') ~ 'Academic',
org %in% c('iNaturalist', 'NatureServe', 'Feeding America') ~ 'Nonprofit',
.default = NA
)
) %>%
select(dimension, indicator, metric, source, org, usda, sector)
get_str(tab)